zongList for Tima

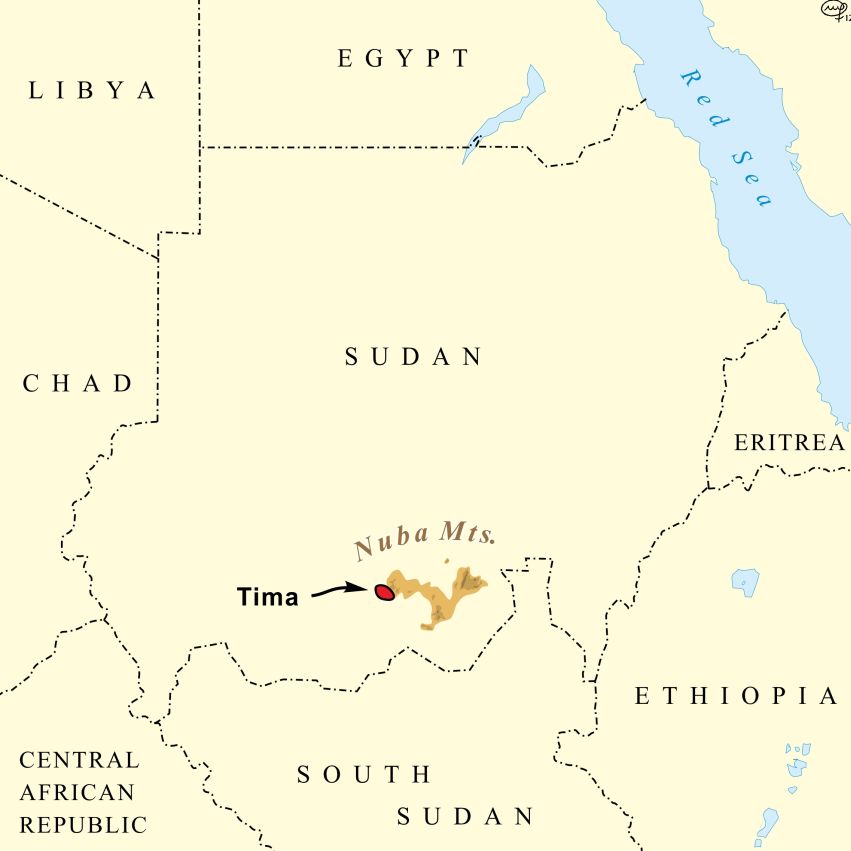
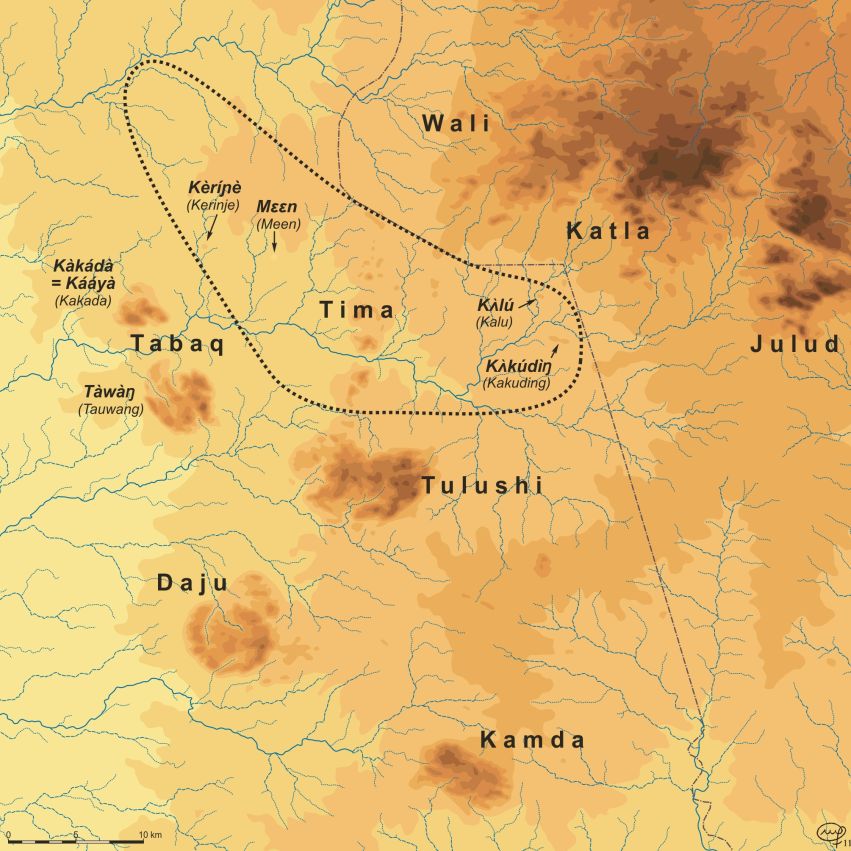
The language of the Tima people – which they themselves refer to as t̪àmáá dùmùrík – is spoken in the Nuba Mountains of north-central Sudan, a residual area with over forty different languages, many belonging to different language families.
According to the standard classification of African languages by Greenberg (1963), there are four language phyla: Niger-Kordofanian (nowadays referred to as Niger-Congo), Nilo-Saharan, Afroasiatic, and Khoisan. According to the same classification, Tima is part of the Katla cluster within the Kordofanian branch of Niger-Congo, which further includes Katla proper as well as Julud. This is also the position taken by Schadeberg (1981:118, 127), who treats the Katla-group as one of the four subgroups of Kordofanian:
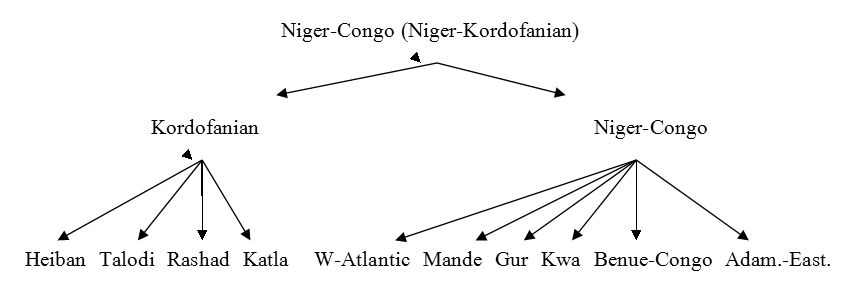
Gerrit Dimmendaal, however, was able to compare new data on Tima (collected since 2005) and other data on neighbouring languages such as Katla and Julud (together with Tima forming the Katla cluster). He therefore suggests that this group of languages “is most closely related to the Rashad group, with which it probably forms a genetic unit. The Heiban and Talodi languages, however, are only distantly related to these, and probably should be treated as a distinct, primary branch of Niger-Congo. The Katla-Rashad group on the other hand shows a considerable degree of grammatical and lexical affinity with Benue-Congo languages and appears to be more closely related to these.” (Dimmendaal 2013:245).
Several factors contribute to the fact that the Tima language and other languages in the Nuba Mountain area are endangered.
Most Tima are multilingual. Multilingualism as such, however, is not the main reason why Tima is an endangered language, as the domains in which such languages are used do not necessarily overlap. However, Arabic, which has become the dominant lingua franca also in the Nuba Mountains, is encroaching upon Tima and other languages in various domains of social interaction between people. But although today Arabic is the only language playing a role in the educational as well as the administrative system of the country in general (cf. Mugaddam 2006, and Mugaddam and Dimmendaal, 2005), due to special circumstances in the Nuba Mountains, English is the language schoolchildren are confronted with first in the Tima area (see also Meerpohl 2012:30f and 199). Arabic is only taught as one of the subjects, while English remains the metalanguage in school.
Due to the political insecurity (more specifically the civil war) in Sudan over the past decades, many groups from the Nuba Mountains have moved to major urban areas such as Khartoum. Today, there are probably over 1000 Tima people in the larger Khartoum area. Members from this community feel that their language is disappearing rapidly in particular in the Khartoum area, because their children are growing up with Arabic, and no longer learn the language of their parents. The Tima people therefore founded a language committee and asked human scientists from Khartoum and Germany to help them documenting and describing their language as well as their culture. By now, next to the dictionary, a number of other publications on various linguistic and ethnological aspects of the Tima culture have appeared that are compiled in the ‘List of publications on the Tima language and culture’.
All primary data are stored in the DoBeS-archive of the MPI in Nijmegen.
References
Dimmendaal, Gerrit J. 2013. The grammar of Knowledge in Tima. In Alexandra Y. Aikhenvald and R.M.W. Dixon (eds), The Grammar of Knowledge, pp. 245-259. Oxford: Oxford University Press.
Greenberg, J.H. 1963 and 1966. [The] Languages of Africa. Bloomington and Den Haag, Mouton.
Meerpohl, Meike. 2012. The Tima of the Nuba Mountains (Sudan). Rüdiger Köppe.
Mugaddam, Abdel Rahim. 2006. Language maintenance and shift in Sudan: The case of ethnic migrant groups in Khartoum. The International Journal of the Sociology of Language 181, 123-136.
Mugaddam, Abdel Rahim and Gerrit J. Dimmendaal. 2005. Sudan: Linguistic situation. In Keith Brown (ed.), International Encyclopedia of Language and Linguistics, Vol. 12, pp. 265-270. Oxford: Elsevier.
Schadeberg, Thilo C. 1981. Das Kordofanische. In Bernd Heine, Thilo C. Schadeberg and Ekkehard Wolff (eds), Die Sprachen Afrikas, pp. 117-128. Hamburg, Helmut Buske.
Alamin, Suzan. To appear a). Adjectives in Tima. In Thilo Schadeberg and Roger Blench (eds.), Proceedings of the Nuba Mountains Languages Conference (Leiden, September 2011). Cologne: Rüdiger Köppe.
Alamin, Suzan. To appear b). Loanwords in Tima. In The Impact of Arabic Language on Sudanese Languages, ed. by Al-Amin Abu-Manga. Khartoum: University of Khartoum Press.
Alamin, Suzan. To appear c). How to ask a question in Tima? The Journal of Sudanese Studies. Institute of African and Asian Studies, University of Khartoum.
Alamin, Suzan. 2012. Negation strategies in Tima. Occasional Papers in the Study of Sudanese Languages, No. 10, pp. 61-74. Kenya: SIL Publications.
Alamin, Suzan. 2012. Prepositions in Tima. Adab Journal 29, Vol.1, pp. 20-39. Faculty of Arts, University of Khartoum.
Alamin, Suzan. 2012. The Nominal and Verbal Morphology of Tima – a Niger-Congo Language Spoken in the Nuba Mountains. Cologne: Rüdiger Köppe.
Alamin, Suzan, Gerrit J. Dimmendaal, and Gertrud Schneider-Blum. 2012. Finding your way in Tima. In Angelika Mietzner and Ulrike Claudi (eds.), Directionality in Grammar and Discourse: Case Studies from Africa, pp. 9-33. Cologne: Rüdiger Köppe.
Bashir, Abeer. In preparation. A description of Tima sounds.
Bashir, Abeer. To appear a). Morpho-phonological alternations in Tima. Adab Journal 30. Faculty of Arts, University of Khartoum.
Bashir, Abeer. To appear b). Conditions of feature specifications in Tima. In Thilo Schadeberg and Roger Blench (eds.), Proceedings of the Nuba Mountains Languages Conference (Leiden, September 2011). Cologne: Rüdiger Köppe.
Bashir, Abeer. 2010. Phonetic and phonological study of the Tima language. unpublished PhD dissertation, University of Khartoum.
Dimmendaal, Gerrit J. 2009. Tima. In Dimmendaal (ed.), Coding Participant Marking: Construction Types in Twelve African Languages, pp. 338-355. Amsterdam: John Benjamins.
Dimmendaal, Gerrit J. 2009. Esoterogeny and localist strategies in a Nuba Mountain community. In Wilhelm J. G. Möhlig et al. (eds.), Language Contact, Language Change and History Based on Language Sources in Africa (SUGIA, 20), pp. 75-95. Cologne: Rüdiger Köppe.
Dimmendaal, Gerrit J. 2010. On the origin of ergativity in Tima. In Frank Floricic (ed.), Essais detypologie et de linguistique générale, Mélanges offerts à Dennis Creissels, pp. 233-239. Paris: Presses Universitaires de l’École Normale Supérieure.
Dimmendaal, Gerrit J. 2010. Ditransitive constructions in Tima. In Andrej Malchukov, Martin Haspelmath and Bernard Comrie (eds.), Studies in Ditransitive Constructions: A Comparative Handbook, pp. 204-220. Berlin: Mouton de Gruyter.
Dimmendaal, Gerrit J. 2013. Where have all the noun classes gone in Tima? In Carole de Feral, Maarten G. Kossmann and Mauro Tosco (eds.), In and Out of Africa. Languages in Question. In Honour of Robert Nicolaï. Paris/Leuven: Peeters Publishers.
Dimmendaal, Gerrit J. 2013. The grammar of knowledge in Tima. In Alexandra Y. Aikhenvald and R. M. W. Dixon (eds.), The Grammar of Knowledge, 245-259. Oxford: Oxford University Press.
Dimmendaal, Gerrit J. To appear. The Leopard’s Spots: Essays on Language, Cognition and Culture. Leiden: Brill.
Meerpohl, Meike. 2012. The Tima of the Nuba Mountains (Sudan) – A Social Anthropological Study. Cologne: Rüdiger Köppe.
Mugaddam, Abdelrahim, and Ashraf Abdelhay. Forthcoming. The politics of literacy in the Sudan: the case of vernacular literacy movements in the Nuba Mountains. In Kasper Juffermans, Yonas Asfahan, and Ashraf Abdelhay (eds.), African Literacies: Ideologies, Scripts, Education. Newcastle Upon Tyne: Cambridge Scholars.
Mugaddam Abdelrahim, and Ashraf Abdelhay. To appear. The Sociolinguistic Profile of Tima Language. In Thilo Schadeberg and Roger Blench (eds.), Proceedings of the Nuba Mountains Languages Conference (Leiden, September 2011). Cologne: Rüdiger Köppe.
Schneider-Blum, Gertrud. To appear. Personal Pronouns in Tima. In Thilo Schadeberg and Roger Blench (eds.), Proceedings of the Nuba Mountains Languages Conference (Leiden, September 2011). Cologne: Rüdiger Köppe.
Schneider-Blum, Gertrud. 2013. A Tima-English Dictionary. Cologne: Rüdiger Köppe.
Schneider-Blum, Gertrud. 2012. Don’t waste words – perspectives on the Tima lexicon. In Matthias Brenzinger and Anne-Maria Fehn (eds.), Proceedings of the 6th World Congress of African Linguistics, Cologne, 17-21 August 2009, pp. 515 - 522. Cologne: Rüdiger Köppe.
Schneider-Blum, Gertrud. 2011. Noun phrase – compound – noun: Some problems with compounds in Tima. In R. Kramer, H. Tröbs and R. Kastenholz (Hrsg.), Afrikanische Sprachen im Fokus, pp. 239-256. Cologne: Rüdiger Köppe.
Schneider-Blum, Gertrud, and Gerrit J. Dimmendaal. 2013. Excite your senses: Glances into the field of perception and cognition in Tima. In Alexandra Y. Aikhenvald and Anne Storch (eds.), Perception and Cognition, pp. 217-249. Leiden: Brill.
You can contact the researchers and language consultants involved in creating this dictionary through Gertrud Schneider-Blum at schneider_blum{at}yahoo{dot}de .
You can contact the developer of the zongList framework, Andrew Margetts at margetts{dot}andrew{at}gmail{dot}com .
This dictionary project was made possible by...
zongList is a web-based dictionary framework, designed to be used through standard browsers and optimised for mobile use. It works both offline and online. It lets you navigate through a dictionary using themed, searchable lists.†
zongList does not at present work with all mainstream browsers. It does work with modern desktop and mobile (for Android) versions of Firefox. The main target mobile platform is Android due to its wide distribution and availability in low(er) cost devices. The mobile browser scene is changing rapidly and it is hoped that more platform/software combinations will be supported in the future, e.g. Opera and Chrome for both desktop and mobile (Android at least).
To begin with you simply choose one of the lists - this will give you all the items in that list, divided into pages of ten items. It is sorted according to the usual order for the language used.†
Sort order for natural languages can be complex and difficult to implement. For dictionaries derived from Toolbox/Shoebox lexicons the sort order is determined in the source program. For other projects sorting may be done with a suitable script written in say Java or Perl (both of which can handle custom 'locale sorting'). The zongList framework doesn't attempt to offer changing the sort order, because in general it is sufficient that each list, and the dictionary itself, is sorted in the normal fashion for the language it is in.
You can then click on 'Filter the list...' and type in a search term (or fragment of one) in the keypad that pops up. This is done by clicking or touching the keys on the pad.‡
Keyboard entry is not supported because of the awkwardness of entering special characters on standard keyboards, and for consistency (i.e. most modern mobile devices do not have a physical keyboard).
You can optionally change whether this term should be at the beginning, end, or anywhere in the list items being searched. This is done by selecting one of the buttons at the bottom of the on-screen key pad: ←, ↔ and → for matching at left-hand edge, anywhere, or right-hand edge respectively.
There are also two 'wildcard' keys: ♣ for any single character, and ♣♣♣ for any number of any characters.†
These wildcards inject 'regular expression' patterns directly into the search term: a single period, '.' for matching any one character, and the sequence '.+?' for any one or more characters (in a non-greedy fashion). If the keyboard is set to 'right to left' (as with say Arabic) then the second sequence will appear as '?+.', but it will function in the same way.
Note that usually you do not have to type much in at all. A small fragment will generally filter the list dramatically so that it contains only items relevant to your search.
To go to the details for a particular item in the list just click on it. This looks up related entries in the dictionary itself. Sometimes there will be a single result and sometimes there will be several. In the second case the results will appear as another list, again divided into pages of ten items if necessary - click the items to see their details.
The keypads that pop up are customised for each list and contain all the necessary characters. You can ignore capitalisation, hyphens and any diacritics (e.g. accents and tone markers) in the language. In other words an a will also find instances of A, à, À, á and Á. Or, for a more complex example, typing abalayɪlɪ would find -àbáláyɪ́↓lɪ́ among other possibilities.
Occasionally a variant key will be included in the keypad if it is deemed to mark an important distinction. For instance a keypad might have both a t and a t̪ key. In this case just typing yantʊ would not find, e.g. yant̪ʊ - you would need to use the t̪ key or a wildcard.
Alternatively a key might be omitted if it is becoming obsolete in the language. For example in Tima the ð is being replaced in modern usage with y; therefore the keyboard only includes the y and this character will also find instances of ð in the dictionary.
Some lists may refer to more than one field in the dictionary if it seems helpful. For example in the Tima dictionary the Tima 'Words' list combines both the head-word and the sub-entry fields and finds hits in both. Similarly the English 'Definitions' list combines both the the actual definition field with the one for literal translations. In both cases this provides for a more natural search experience since closely related items are grouped together.
Within many detail views there will be other links. Some of these may be cross-references that take you to another, related entry in the dictionary. Other links are to associated information: documents, pictures, sound and video files, other web sites.
Some of these links should always work because the media files have been added to the base program and so will be stored locally on your machine (provided you and/or your software have permitted such storage); others will only work if there is a connection to the internet because the files have not been added to the base (this is to prevent overloading your phone or computer memory).
Every page has a 'back' or 'close' button to help you go back to where you started. If you get lost, just refresh the page in the browser.
zongList is written in HTML5, CSS3 and JavaScript; the lexicon data is in JSON (JavaScript Object Notation). It uses some external JavaScript libraries (see 'Acknowledgements' below), but no other plugins or extensions. It can be modified and used as the basis for other online dictionaries without limitation, and all of the components are freely available.
More detailed information on both the framework and the nature of the data is available at the zongList Guide page, but the key points that distinguish zongList from some other solutions are:
Some of these features are currently affected by the fact that mobile browsers are not as mature as their desktop counterparts. For instance not all mobile browsers currently have good support for HTML5 audio/video. Also local storage is still limited both in capacity and the type of data that can be easily stored.
It is likely that many of these problems will over time disappear given the rapid development of mobile browsers. At present (October 2013) the following platforms/browsers provide an adequate environment:
As mentioned, the underlying dataset is in JSON, a plain-text format which is both succinct and easily parsed by the JavaScript engine. This makes JSON very suitable for mobile browser use (where file size and processing power are limiting factors to a far greater degree than for conventional computers). JSON has become a de facto standard for data storage and transmission in very many on-line situations so having the data in this form increases the potential for other software and services to use the underlying information if desired. It is also quite easy for a human to read JSON.
For the Tima dictionary (which is the prototype lexicon for zongList) the initial format for the data was SF (Standard Format) as used in Toolbox/Shoebox. This is also a plain-text format and also relatively easy for a human to read. Toolbox imposes few constraints on the construction of an SF file and things like field hierarchy are handled in a separate, associated 'database type' file. This makes SF rather too forgiving of variability in human data input, which means that any kind of conversion process needs to check for potential errors and edge-cases in the source file. This is the main challenge for re-using Toolbox/Shoebox data in any other program, zongList included.
The source data need not be in SF however. Anything that is capable of being transformed to JSON is a good candidate. XML files are often quite suitable and there are parsers available to convert XML to JSON. It should be said that there are certain XML structures that do not permit a straightforward translation to JSON (though it can be done). However these are the same kind of structures that make it computationally more expensive for most programs to parse XML than JSON (which is closer to how common programming languages structure both data and logic).
Despite the challenges of converting SF or XML to JSON I believe that the JSON format provides a sound scaffolding for many lexicons. It is expressive enough to describe most types of complex data hierarchies (without any kind of external 'type file' or schema), yet straightforward for a program to 'consume', and far easier to check for errors and anomalies than SF. So the JSON file underlying a zongList dictionary would be suitable both for preserving, and also for further developing or exposing the lexicon. And because JSON can capture internally any essential hierarchical structures, subsequent re-conversion for use within Toolbox or other, XML based, software would be relatively simple.
Adapting zongList for use with other datasets (or to achieve different ends) will require some skill in the underlying programming languages and concepts, and particularly in the area of data checking and conversion. I am afraid there are no plans, or funds, to make this a more sheltered experience akin to using, say a Content Management System. However it was my intention to develop not just a single-use solution but a framework that could be the basis for similarly structured lexicons, e.g. Toolbox/Shoebox databases, particularly those using the Multi-Dictionary Formatter (MDF) set of markers. So I encourage anyone who would like to adapt zongList for their own data to contact me on margetts{dot}andrew{at}gmail{dot}com.
The development of zongList was made possible through the financial support of the Dokumentation bedrohter Sprachen (Documentation of Endangered Languages or 'DoBeS') program of the Volkswagen Stiftung, and through the faith that the Tima project within that program (and most specifically Gertrud Schneider-Blum) placed in me. I am most grateful.
The zongList framework uses several JavaScript code libraries created and generously made available by many clever people. These libraries are: jQuery, jQuery Mobile, jquery.keypad.js, and doT.js. Details of licensing and authorship may be found in the source code for each library. Again, I am most grateful.
If you adapt zongList please retain these acknowledgments.
© Andrew Margetts 2013